构建让基础模型持续进化的基础设施
基础模型正在成为科技公司最后的技术壁垒。它的竞争对象不只是一次性训练得到的静态权重,而是持续运行、持续观测、持续自我演化的复杂系统。真正的壁垒不只来自参数规模、训练语料或单点算法,而来自更深层的系统能力:将计算、数据、模型、环境、反馈和安全评估组织成闭环,让智能能够在真实环境中积累经验、修正行为,并走向持续学习与可验证、可控的递归自我提升。
我们构建面向下一代基础模型的全栈演化基础设施,覆盖云原生 AI 集群、大规模训练与后训练、在线推理、agent rollout、数据回流、观测评估和安全验证,也连接底层 GPU kernel、分布式训练 runtime、模型服务系统、轨迹数据中间表示和强化学习闭环。
在这个系统中,模型发布不是终点,而是下一轮自我改进的起点。真实部署产生新的行为轨迹,工具调用暴露新的能力边界,失败案例被结构化为可复用的经验。目标是把基础模型从一次性训练产物,转变为持续进化的智能系统。
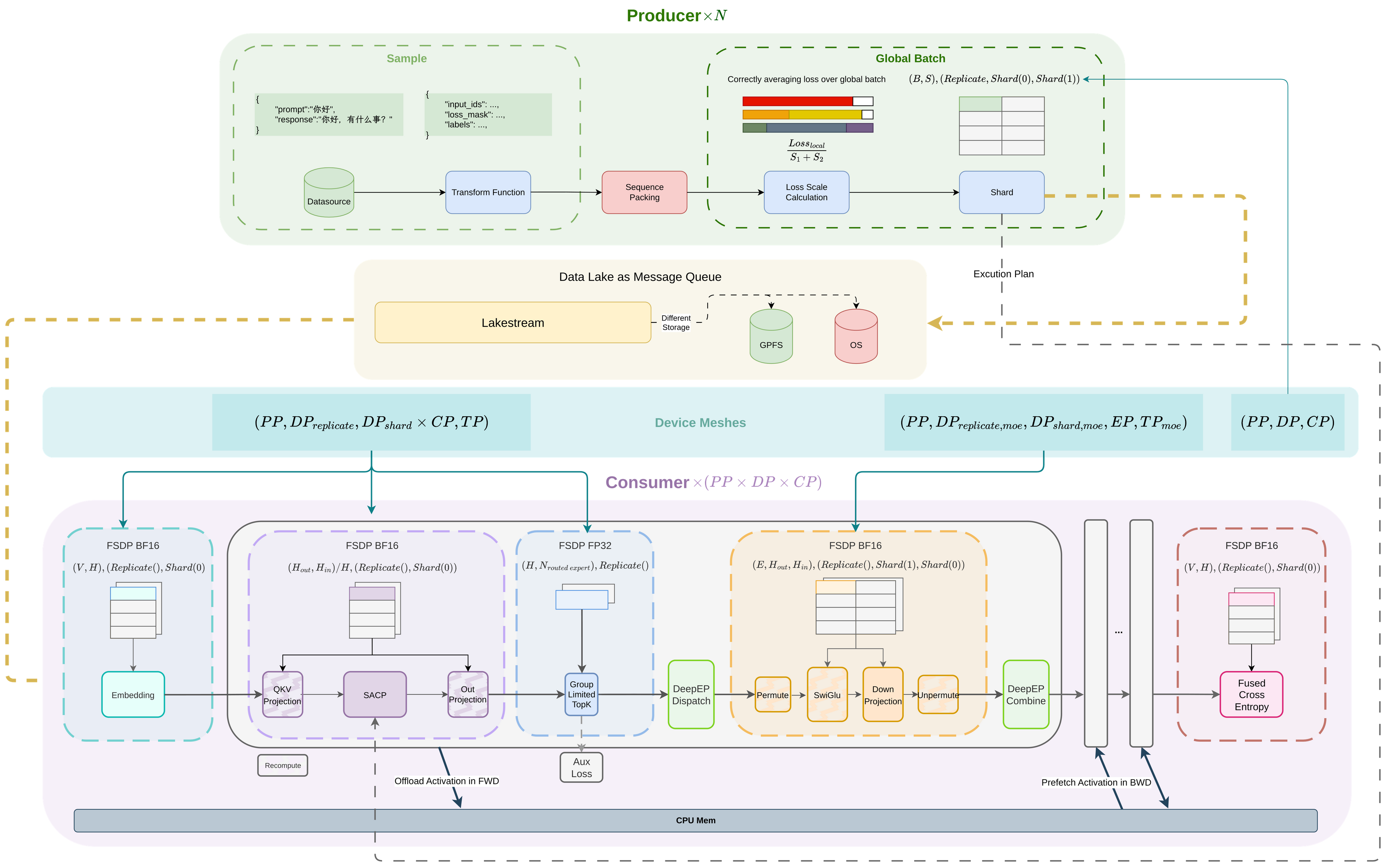
基础模型训练引擎
基础模型的能力增长,不是一次性参数固化,也不是外部系统单向注入知识,而是模型在任务、环境和反馈中不断形成新的行为能力。训练系统的角色,是为这种自主进化提供可规模化、可复现的经验循环:数据、反馈、rollout、评测和人类偏好共同构成模型面对世界、试错、修正和泛化的条件。
我们构建面向万亿级参数模型的分布式训练引擎,支撑 Mid-train、Post-train、多模态训练和 MoE 训练,让这种自主进化过程在大规模集群上保持高吞吐、稳定性和可扩展性。

- 支撑万亿级参数规模模型的 Mid-train 与 Post-train。
- 覆盖 Dense、MoE、VLM、Diffusion、VLA 等模型形态。
- 围绕并行策略、通信优化、Attention 算子和训练 pipeline 提升端到端效率。
- 在 DeepSeek、Qwen、GPT-OSS、Gemma、Flux、Wan 等模型中验证训练性能。
| 模型 / 系列 | 规格 / 版本 | MFU |
|---|---|---|
| DeepSeek-V3.1 | 685B-A37B | > 40 |
| GPT-OSS | 120B / 20B | > 30 |
| Qwen3 | 235B-A22B / 30B-A3B | 35 ~ 40 |
| Gemma4 | gemma4-31B,256K 上下文 | > 35 |
面向现代模型架构的全链路训推优化
下一代模型负载更加动态:Agent 任务会产生长而高方差的轨迹,Deep Research 会引入检索、浏览、阅读和多步推理,长视频和多模态任务会扩展上下文窗口,MoE 模型则把稀疏激活、专家通信和负载均衡推到系统瓶颈中心。这些 workload 不适合被简化为固定长度、静态 batch、均匀计算的语言模型训练问题。我们围绕 frontier workloads 构建长上下文与稀疏模型训练能力,让复杂任务产生的数据能够以更低成本、更高吞吐和更稳定的方式被吸收到模型中。
超长序列分布式训练框架
在后训练,尤其是 Agent 场景中,长序列问题会被显著放大。Trajectory 长度受任务步数、环境反馈、工具调用和中间推理过程影响,天然呈现高方差与长尾分布;少量超长样本会显著拉高最大序列长度,而统一 padding 会带来大量无效 attention 计算和显存浪费。同时,后训练数据具有持续生成、动态筛选和在线混合的特点,难以依赖预先分桶或固定长度阶段训练规避长度差异。
真实 agentic training workload 要求系统理解 batch 内部结构,而不是只处理 token 数量。为此,我们构建了以拓扑感知的序列并行框架(SACP,Sequence-Aware Context Parallel)为核心的长序列高效训练方案,从计算、通信、负载均衡和显存管理层面提升真实长序列数据下的全局资源利用率。
- 拓扑感知的序列并行框架 SACP:SACP 的核心思想是把 packed sequence 的真实拓扑暴露给 runtime。在 packing setting 下,SACP 并非把长序列简单视为均匀切分的 token block,而是显式感知 packed sequence 内部的样本边界、注意力拓扑和跨 rank 计算关系,将混合 attention 计算抽象为可编译的序列并行策略中间表示。系统可以根据给定 batch 的真实结构即时生成通信与计算计划,动态决定 attention block 的执行 rank、stage,以及 Q/KV/O/dQ/dKV 的跨 rank 流转方式,从而减少 straggler、降低无效通信,并提升通信与计算重叠效率。


- 统一注意力计算后端:围绕 SACP,我们构建统一的 attention 算子库,将 Ulysses Async GQA/MLA、FlashAttention / varlen FA、FlexAttention 等 backend 纳入统一接口,以适配不同模型结构、attention pattern 和硬件约束。对于 Gemma4 等具有特殊 hybrid attention 结构的模型,我们实现了针对性的高性能算子,使 SACP 可以作为上层 runtime,根据 batch 结构、CP 拓扑和模型 attention 形态组织合适的 inner attention backend。这里的关键不只是支持更多 kernel,而是把 attention backend 从静态组件提升为 runtime 可调度资源。
- 长上下文资源协同优化:为提升端到端效率,我们将 SACP 与 CP-aware / kernel-aware balanced packing、selective recompute 和 selective offload 一同设计。Balanced packing 在 batch 构造阶段引入面向 FA/SACP 的代价模型,根据 attention 计算量、block 分布和跨 rank 调度成本构造更均衡的 global batch,减少长尾样本导致的 straggler;selective recompute/offload 通过选择性重算、异步卸载和按层预取控制 activation memory 峰值。整体方案使长序列后训练在扩展上下文长度的同时保持更高的全局计算资源利用率。

SACP 在长序列配置下,相比 TE FlashAttention、DistFlashAttention、Torch CP 和 FlashAttention2 等主流序列并行算子取得更低的 FW/BW 总时延,并在更高并行度下避免传统 Torch CP 的 OOM 问题,体现出更好的性能和可扩展性。端到端方案支撑 DeepSeek V3/V3.1、Qwen3/Qwen3-VL、Gemma4 等主流模型在各自最大上下文长度下高效训练,使长序列后训练能够在扩展上下文长度的同时保持稳定吞吐。
混合专家模型训练优化
MoE 是扩大模型容量的重要路径,但在万亿参数模型后训练中,它带来的系统问题也更加尖锐。MoE 后训练的效率瓶颈主要来自通信、计算和负载均衡:任务类型、样本长度、工具调用、推理轨迹和数据混合比例都会改变 token routing 分布,使 expert 负载更容易出现不均衡。
同时,MoE 的稀疏激活会带来跨设备 token dispatch / combine,以及大量小规模、动态形状的 expert GEMM,导致通信和计算都更难稳定提高 GPU 利用率。因此,MoE 后训练的关键不只是支持 expert parallel,而是围绕 expert 通信、专家计算、并行切分和负载均衡形成端到端优化。

- 高效专家并行通信:基于 DeepEP 接入 expert parallel runtime,完成 fused dispatch / combine、异步通信、通信流 buffer 管理和 expert 权重按 EP 维度切分,降低 token routing 对主计算路径的阻塞。
- 面向混合专家的高性能计算优化:针对 MoE MLP 中大量小规模、ragged GEMM,集成 Expert Group GEMM、FP8 / DeepGEMM 等高性能路径;同时,针对 GPT-OSS 等模型中的 MoE bias、SwiGLU、down-proj backward 等热点,设计 CUTLASS fused MoE kernel,减少 D2H 同步、额外 kernel launch 和中间激活写回。
- MoE-aware sharding 与 prefetch:不将 dense block、router 和 expert compute 作为同质模块统一处理,而是根据它们不同的通信模式、精度需求和梯度归约方式,分别配置 sharding、mixed precision、reshard 策略和 prefetch 路径,减少 EP 与 FSDP/HSDP 组合时的额外通信开销。
- Sequence-aware load balancing:针对后训练中 packing、长序列和 context parallel 带来的 routing 分布变化,引入更贴近真实 sequence 结构的负载均衡统计,缓解 expert hotspot 和 rank straggler,提升长跑训练中的吞吐稳定性。
通过这些系统化集成与框架层优化,我们能够支撑万亿参数级 MoE 模型在后训练阶段保持较高的计算资源利用率和稳定吞吐。
构建模型自主进化和后训练的基础设施
后训练阶段的核心问题,是如何把模型在真实环境中的行为转化为下一轮自我改进的经验。这要求训练、推理、rollout、评测和数据系统之间形成低延迟闭环:模型生成行为,系统记录行为,评估器识别成功与失败,训练引擎促成模型形成新的行为能力,推理服务再消费更新后的模型。在这个循环中,高延迟 checkpoint、割裂的消息格式和不可复现的轨迹都会削弱闭环演化效率。
Etha:强化学习中的高效张量同步
On-policy Distillation 和强化学习后训练要求模型在训练更新与推理采样之间高速循环。传统 checkpoint 同步延迟高、IO 压力大,gather-broadcast 又容易产生全量权重副本,难以支撑万亿参数和 MoE 模型的高频迭代。Etha 的核心目标,是把权重同步从文件级 checkpoint 操作变成 tensor shard 级在线重分布,让刷新后的模型权重直接同步到 rollout 环境中,降低 stale data,提升闭环演化效率。

- 跨作业张量重分布:将 PyTorch DTensor redistribution 扩展到独立启动的训练与推理作业之间,支持不同 DeviceMesh、Placement 和并行切分方式。在解耦式 RL 中,训练集群可以按照训练吞吐最优的并行策略组织模型,推理集群可以按照 vLLM 服务吞吐最优的并行策略组织模型,Etha 负责在两种异构布局之间完成在线重分布。在 32 卡 DeepSeek 全量权重同步场景下,端到端同步耗时约 2.5s,能够支撑 on-policy distillation 和 RL 后训练中的高频权重刷新。
- 零副本 M-to-N 传输:根据源端和目标端真实 shard 关系直接建立 rank-to-rank、slice-to-slice 通信路径,源端只发送自己持有的 shard,目标端只接收所需 shard,避免中间 rank 聚合完整权重。相比 gather-broadcast,这一路径减少显存冗余和无效数据搬运;在 25 个 tensor 的 batch transfer 测试中,M2M + bucket 路径达到约 270 GB/s,相比 gather-broadcast 的约 140 GB/s 接近 2 倍提升。
- CUDA IPC + NCCL 直连:Etha 采用 Worker-Agent 分离架构,Worker 只负责注册 tensor 和提交同步请求,Agent 通过 CUDA IPC 获取 GPU tensor 句柄,并直接执行 NCCL send / recv,避免 CPU staging、host roundtrip 和 checkpoint IO。端到端评测中,Etha 等效带宽达到约 33 GB/s/卡,高于 Perplexity 方案的约 12 GB/s/卡和 Ant 方案的约 3 GB/s/卡。
- Bucket 化小 tensor 传输优化:真实大模型 state dict 中存在大量 norm、bias、router、MoE 辅助参数等小 tensor,逐 tensor 传输容易受到通信启动开销影响。Etha 在 batch level 将相同通信模式的小 chunk 聚合为 bucket,使小尺寸 tensor 传输性能提升约 3 到 5 倍,显著降低完整权重同步中的长尾开销。
- 低侵入集成训练与推理框架:Etha 复用 PyTorch 原生 DeviceMesh + Placement 抽象,不要求重写模型结构或引入新的并行描述语言。训练侧通过 TensorBus 注册 DTensor shard,推理侧通过 vLLM worker 注册目标权重 tensor,双方通过统一 batch id 完成在线 send / recv。
- 面向解耦式 RL 的实践沉淀:Etha 可低成本接入现有分布式训练框架和 vLLM rollout 服务,并用于 vLLM-RL 解耦式 RL 权重同步实践。
LLMM:统一的 LLM Message 中间表示
现代 LLM 系统的行为并不只存在于模型输出中。一段完整会话可能被拆散在 Responses API、Messages API、GenAI、Codex CLI、Claude Code、scaffold、tool runtime 和推理后端之间。提供商 API 形态存在差异且演化速度快,schema、tool call、reasoning state、error、usage、streaming 和 metadata 都可能不同;同一段 agent 行为会在多个系统之间反复转换,并逐渐混入接口噪声。
如果训练系统只能看到最终 response,它学到的就不是完整行为,而是被接口折叠后的残影。LLMM 借鉴 MLIR,引入 typed IR ladder,让不同 API 先进入各自的 surface dialect,再通过 lift / lower 汇入中性的 agentic 表示。多轮对话、工具调用、reasoning state、错误和 usage 因此可以围绕稳定 IR 组织,并通过 trace / replay 保留转换过程中的语义变化。LLMM 连接 Agent 后训练、回放评测、线上推理和 scaffold 接入,目标是把高级 API 逐层降低到 chat、completion 和 token 层,让训练系统学习 agent 行为本身。

- 统一抽象:把训练对象从 response 升级为 trajectory。后训练样本以完整的 agent 行为链路为单位:模型如何理解任务、规划步骤、调用工具、处理失败并继续推进,直到完成目标。接口差异被隔离在系统边界之外,不进入核心行为表示。
- 多厂商一等支持:Responses、Messages、GenAI、Codex、Claude Code、BCE、Antigravity 等链路可以保持各自形态,但格式差异、schema 修正、vendor quirk 和兼容性补丁都收敛在边界层处理,不污染核心的 agent 行为表示。系统因此能够快速吸收新的模型接口和 agent runtime,同时保持训练、评测和回放语义稳定。
- 训练、评测和线上推理共享同一份事实:trace / replay 机制记录轨迹转换、执行结果、loss 事件和运行时状态,使同一段 agent 行为既可以用于训练样本构造,也可以用于失败复现、评测回放和线上行为分析。后训练系统不依赖不可复现的日志碎片,而是拥有可追踪、可重放、可学习的行为账本。
- 连接高级 Agent API 与底层 token 执行:LLMM 将上层 agent API、chat、completion 以及更底层的 token 表示连接起来,让一段 agent trajectory 能够从框架接口贯通到模型输入的 token stream。
Cloud-native AI Ops
基础模型闭环从大规模部署开始。只有模型能够被稳定服务、持续观测和系统评估,真实使用中的模型行为才可能重新变成训练信号。因此,云原生能力不是背景设施,而是基础模型持续演化的运行时底座:它决定模型能否被大规模使用,能否产生足够高质量的行为数据,能否在失败中快速定位问题,并能否把线上反馈转化为下一轮训练输入。
- 构建云原生 AI 集群和 GPU 资源调度平台,支撑训练、推理、后训练和 rollout 任务的统一调度,并支持分钟级大规模集群拉起与小时级弹性资源复用。
- 支持大规模模型部署、高并发推理服务和沙盒 rollout,为 on-policy 数据生成提供稳定运行环境,并在单一集群上支撑超过 10k 个沙盒的并发训练和推理。
- 建设日志、观测、评估和真实使用数据回流机制,让线上模型行为能够被结构化、分析并进入下一轮训练。

Lakestream:数据湖原生的数据中间件
多模态基础模型训练生命周期需要支撑大规模文本、多模态数据、rollout 轨迹、工具调用日志和评测样本的流式处理。这些数据既有离线批处理特征,也有流式生成特征;既需要长期存储,也需要被快速消费。
传统 pipeline 往往在消息队列、对象存储、离线表和训练数据集之间反复搬运数据,造成重复存储、延迟堆积和计算浪费。Lakestream 的设计目标,是将数据湖本身变成消息队列,通过无服务器方式消除数据重复、存储瓶颈和计算瓶颈。

- 构建 Lakestream 和多模态分布式数据基础设施。
- 将模型部署、评测、rollout、后训练采样和训练消费连接成持续数据流,缩短新行为、新任务和新经验进入模型迭代的路径。
- 通过数据与计算解耦、流式数据管线和多模态数据管理,降低离线 pipeline 的等待成本,支撑从真实使用到模型自主进化的端到端闭环。
从系统视角看,Lakestream 不只是数据基础设施,而是模型演化闭环中的行为信号传导层:它让信号能够在部署、评测、训练和再部署之间持续流动。
大规模智能体训练系统及环境
后训练任务覆盖 Math、Code Agent、Deep Research 和多轮工具调用,训练目标以完整交互轨迹为单位,而不是只优化一次 response。模型需要在任务过程中持续思考、写代码、调用工具、读取网页、执行程序、观察反馈并修正策略;同时,trajectory 长度、执行耗时、工具结果和失败模式都高度动态。围绕这一类 agentic workloads,我们构建面向 Math、Code Agent 和 Deep Research 的后训练实践体系。

- 高并发沙盒化 Agent Rollout:面向真实工具调用和代码执行场景,构建轻量级沙盒 rollout runtime。模型以 code-as-action 的方式在 Notebook / REPL 环境中完成 “think → code → execute → observe” 循环,每条 trajectory 在独立沙盒中运行,隔离文件系统、临时 workspace、日志和执行状态,避免样本间污染和不受控代码影响训练环境。相比重型容器,轻量沙盒启动成本更低,更适合高并发 agent rollout。
- 训推解耦的并发采样系统:将 CPU 侧 agent 执行与 GPU 侧模型推理解耦。GPU inference server 只负责模型生成,沙盒 worker 负责工具执行、网页读取、代码运行和轨迹保存;TaskServer / worker pool 负责远程任务调度、并发控制、超时、失败重试和清理。该设计使长耗时、IO 密集、失败模式复杂的 agent 执行能够独立扩展,不阻塞训练和推理资源,也让 GPU 侧高吞吐生成与 CPU / 环境侧高并发执行分别优化。
- 面向多步 Agent 的 RL 算法与训练策略:针对 agent 任务中奖励天然发生在 step / trajectory 级别,而语言模型优化发生在 token 级别的问题,探索 Agentic Policy Gradient、multi-step verifiable reward、bi-level advantage 以及 REINFORCE++ / KL / DAPO-style filtering 的组合训练 recipe。完整的 think-code 片段被视为 agent action;奖励由答案正确性、格式约束、代码执行质量、长度约束等可验证信号组合得到;step-level reward 进一步映射到 token-level policy optimization。训练过程中,对同一任务采样多条 trajectory,并过滤全对或全错等缺少有效 advantage 信号的 group,在样本不足时继续生成,以提升训练样本的信息密度和策略更新稳定性。核心判断是 agent 后训练不只是让模型多调用工具,而是建立一种把多步行为、环境反馈和 token-level policy learning 对齐起来的训练范式。
- 从 Math 到 Deep Research 的实践闭环:围绕数学推理、代码执行、QA、多跳检索和 Deep Research 类任务,形成从数据处理、沙盒 rollout、奖励计算、RL 训练到评测的完整闭环。L0 实践覆盖 4B / 7B / 32B 等模型规模,并在 agentic QA、multi-hop reasoning 和 search-style tasks 上验证多步工具型后训练的收益。这条路径把 agent 能力从 prompt engineering 和 scaffold engineering 推向模型本体训练,使模型逐步学习如何在环境中行动、观察、修正和完成任务。
基础设施与算法协同设计
封神榜是中国最早的开源大模型系列,总体下载量达到数百万,包含以下模型:
- Taiyi:最早发布的中文文生图 Diffusion 模型,在高质量中文图文对上进行大规模 Mid-training。
- Ziya 系列模型:首个完成 RLHF 的中文大规模 Chat 模型,在 SuperCLUE 上获得开源模型第一名。

fs SUS-Chat-34B 在发布版本评测中位列 OpenLLMLeaderboard 第一,超越同一阶段的 DeepSeek 67B,并被开源社区广泛采用。开发者将 SUS-Chat 与 Nous-Hermes-2(Hermes agent 团队开发)合并后,再次取得第一。
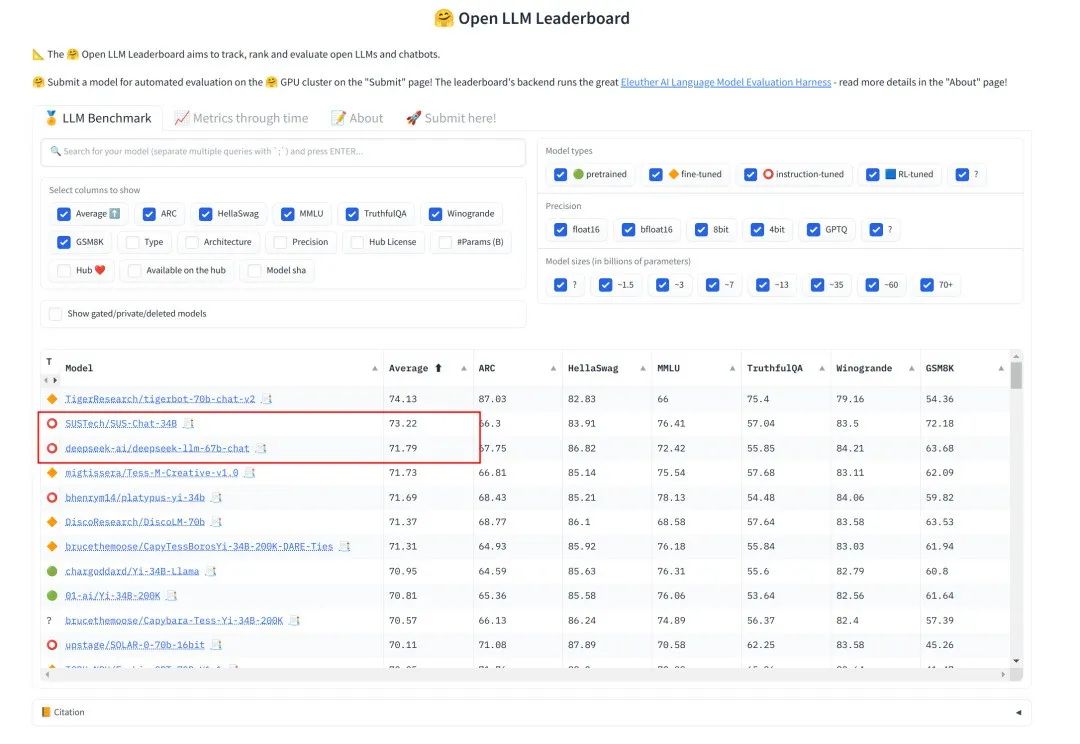
SUS-Chat-34B 端到端智能体开源工作 L0 验证了多步工具型 Agent RL 相对于单轮文本 RL 的可行路径,是全球最早公开分享多步工具型 Agent RL 训练实践的项目之一。

improvement